¿Qué es el Análisis de Componentes Principales?
El Análisis de Componentes Principales (ACP) es la llave maestra de la estadística multivariada y, por consiguiente, del control multivariado. Encierra un conjunto de procedimientos que nos ayudan a entender la variabilidad conjunta de nuestros datos, y es la base de muchas otras metodologías aplicadas al mundo multivariado.
Entender el ACP es entender la variabilidad multivariada, base para el control, y dominar estos conceptos te abre las puertas para entrar a un mundo que parecía complejo, pero que en realidad no tenía que serlo.
Entender ACP te permite, de forma directa, acceder a
- diseñar sistemas de control multivariado,
- medir la multicolinealidad,
- reducir dimensiones,
- identificar variables latentes,
- potenciar la clasificación y la regresión de componentes principales,
- e identificar puntos atípicos,
- entre otras cosas.
¿Todavía no estás convencido? Aquí te va más, entender ACP facilita, de forma indirecta, el entendimiento de los «primos» metodológicos como:
- regresión y clasificación por mínimos cuadrados parciales,
- análisis discriminante lineal,
- análisis de factores
Todos estos métodos trabajan con un mismo ADN matemático: proyectan nuestros datos en nuevos ejes que simplifican la estructura de los mismos. Si hay una metodología en la que vale la pena profundizar, esa es el ACP. Haciendo una analogía, esto es como aprender tu primer lenguaje de programación, una vez entiendes la lógica de uno, entiendes a los demás, pues en el fondo sabes que comparten el mismo ADN.
Por supuesto, no lo voy a negar, puedes saltarte el entendimiento del ACP y pasar directo a la aplicación. Pero esto sería usar recetas para hacer estadística sin entender primero qué significa la variabilidad. Sí, puedes hacerlo, de forma mecánica, siguiendo recetas de cocina creadas por alguien más, pero las aplicarías sin tener ese entendimiento y habilidad fina que sólo el conocimiento de la causa te da. Creo que eres mejor que eso.
En este artículo ahondaremos en los conceptos que están detrás del ACP, le daremos un sentido geométrico intuitivo al proceso, y paso a paso iremos recorriendo la terminología, definiciones, y herramientas matemáticas y computacionales para detonar su potencial. En este artículo nos centraremos en el caso de sólo dos variables, pues es más intuitivo y lo podemos graficar. Sin embargo, a través del uso del álgebra encontraremos que la generalización a más variables es directa y transparente.
Prepárate para abrir los ojos en un viaje del que no te arrepentirás.
El Concepto
El ACP es el análisis de la variabilidad conjunta de los datos por medio de la identificación de las principales direcciones de variación alrededor de su centro de masa.
Los datos tienen variación, y la dirección en que oscilan, o varían, es a lo que llamamos en este contexto un componente. De todas las direcciones en que pueden variar los datos, hay unas direcciones que destacan por su magnitud y relación.
Estas direcciones de variación que más destacan entre nuestros datos, bajo algunos criterios que formalizaremos, las llamamos componentes principales, un nombre corto para indicar los vectores, o direcciones, principales de la variación conjunta. La palabra variación viene implícita y usualmente no se agrega al nombre de la metodología.
En el ejemplo de la Figura 1 se pueden apreciar estos vectores de variación atravesando la nube de datos. Estos componentes, como se aprecia en la figura con dos variables, son perpendiculares entre sí. Esto no es coincidencia, es algo que viene dado por diseño de los componentes. Cuando tenemos más de dos variables, tenemos más de dos direcciones de variación principal, y esta propiedad de mutua perpendicularidad se mantiene, sólo que con más de dos variables la propiedad de perpendicularidad pasa a ser llamada ortogonalidad.
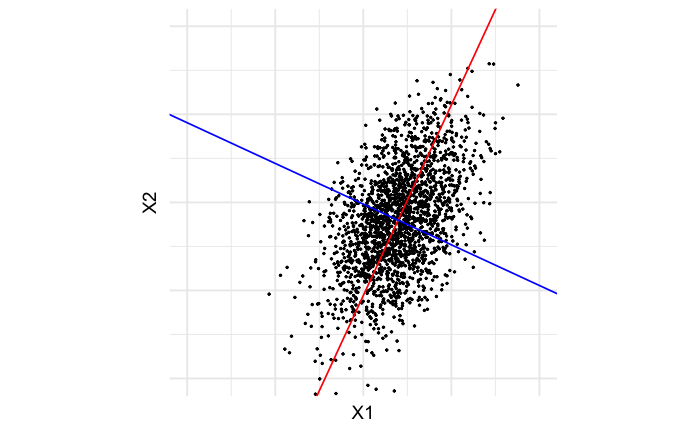
La Rotación del Espacio
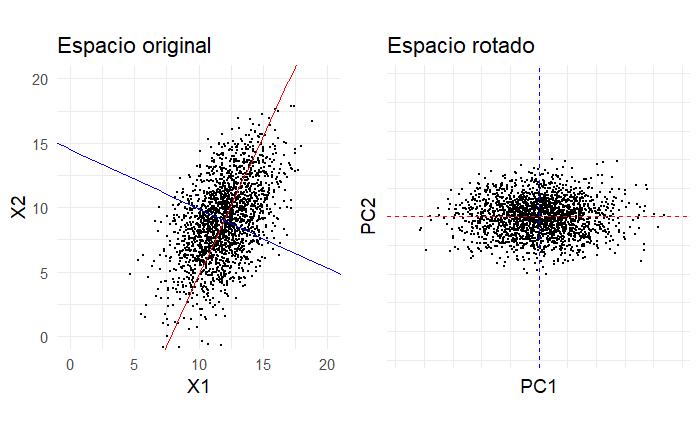
Una vez hemos identificado los componentes principales de nuestros datos, podemos hacer uso de ellos como si fueran un nuevo sistema de coordenadas donde proyectar nuestras observaciones. Esta proyección, como se ilustra en la Figura 2, es una transformación que mueve las observaciones hacia un nuevo sistema de coordenadas definido por los componentes principales. Esto crea una especie de rotación del sistema de coordenadas original hacia un nuevo sistema donde:
- las nuevas variables no están correlacionadas,
- la primera dirección captura la máxima variabilidad,
- las direcciones subsecuentes (en caso de haber más de dos) capturan la variabilidad restante bajo ortogonalidad.
También funciona para más de dos variables
En los ejemplos de las figuras 1 y 2 se han mantenido dos variables para facilitar la comprensión del concepto en su mínima expresión.
Con más de dos variables la visualización se complica, y con más de tres dimensiones hablamos del hiperespacio.
Los conceptos ilustrados se entienden mejor con dos variables, y se mantienen con cualquier número de variables. Así que no te preocupes, veremos que las ecuaciones que utilizaremos son directamente generalizables a más de dos dimensiones.
El Proceso de Análisis de Componentes Principales
Los elementos más importantes del ACP los podemos resumir en cinco pasos:
- Centrar datos
- Calcular la matriz de varianza-covarianza
- Obtener los componentes principales
- Proyectar
- Usar los componentes para algo práctico
Ilustraremos cada uno de estos pasos siguiendo un caso de estudio de la industria alimenticia donde hay sólo dos variables involucradas. A lo largo de las explicaciones iré introduciendo conceptos de álgebra matricial que nos ayudarán a generalizar nuestras observaciones y resultados.
Caso de Estudio: Calidad de Granos de Maíz
Consideremos dos variables medidas en muestras de maíz:
- : Contenido de humedad (%)
- : Contenido de proteína (%)
Ambas variables son comunes en control de calidad de alimentos y están correlacionadas entre sí.
Una muestra de estos datos se observa en la Tabla 1. Esta tabla, sin los encabezados, forma una matriz de datos de dimensiones . Llamaremos a esta matriz de datos .
| 10.2 | 5.6 |
| 13.1 | 9.5 |
| 14.1 | 11.9 |
| 8.1 | 2.5 |
| 13.6 | 9.8 |
| 14.8 | 9.5 |
| 10.4 | 7.7 |
| 12.7 | 6.7 |
| 11.2 | 7.3 |
| 12.1 | 5.8 |
| 9.7 | 8.4 |
| 11.3 | 5.8 |
| 12.0 | 6.2 |
| 12.8 | 8.8 |
| 15.7 | 10.7 |
| 13.6 | 7.9 |
| 14.5 | 6.0 |
| 12.7 | 5.4 |
| 11.3 | 6.4 |
| 16.0 | 15.7 |
Estas variables son muy conocidas en el proceso que estamos utilizando como ejemplo. Además de esta muestra reciente de datos mostrada en la Tabla 1, se conoce por estudios históricos que la humedad promedio corresponde a 12%, y la proteína promedio a 9%. Además, los estudios de capacidad del proceso han demostrado que la desviación estándar de la humedad es de 2 y de la proteína es 3, con una correlación entre las variables de 0.5. Se puede decir que estos son los parámetros conocidos de este estudio de calidad de granos de maíz.
Analizamos con mayor profundidad estos parámetros conocidos. Matricialmente estas propiedades estadísticas las podemos expresar con un vector de medias
,
y una matriz de varianza-covarianza de
.
Para entender , la llamada matriz de varianza-covarianza, o simplemente matriz de covarianzas, necesitamos entender cómo está construida. El primer elemento de la diagonal, corresponde a la varianza de , esto es . El segundo elemento de la diagonal corresponde a la varianza de , esto es . Los demás elementos son las covarianzas, o variación conjunta, de con y con , correspondientemente llamadas y , sin el exponente cuadrado. Por propiedades de las covarianzas . El valor de la covarianza lo podemos obtener de la fórmula de la correlación . Puesto que la correlación es 0.5, la covarianza es la única desconocida. Resolvemos para y encontramos que su valor es 3, y este valor lo colamos en la matriz . Recordemos que la correlación de A con B es igual que la correlación de B con A, por eso el número 3 aparece dos veces en la matriz.
Si no conocemos previamente el vector de medias y la matriz de varianza-covarianza, estos los podemos estimar a partir de nuestros datos. Pero como en este caso ya los conocemos, utilizaremos los valores conocidos. De esta manera quedará evidencia que el análisis de componentes principales depende del valor que definamos para y , cuyos valores pueden estimarse o provenir de valor histórico conocido.
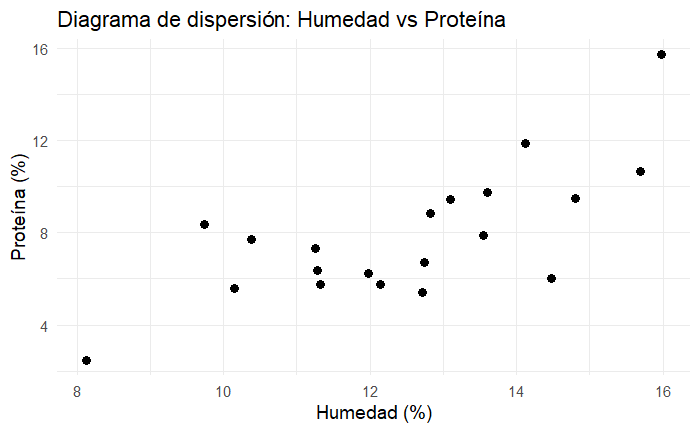
En la Figura 3 se puede apreciar la relación de las observaciones con las que estaremos trabajando. Los lotes con mayor humedad tienden a tener mayor contenido de proteína, hay una ligera dependencia entre ambas mediciones. Además, la variabilidad en proteína es mayor que en humedad (observa bien las escalas en los ejes y no te dejes engañar por la gráfica que parece estar estirada en el eje de la humedad).
Paso 1: Centrar Datos
Aquí hay que organizar los datos en una matriz con observaciones y variables. Esto ya lo tenemos hecho en la Tabla 1 y hemos estado llamando matriz , donde hay observaciones de números reales y dimensiones. Esto es, .
Centramos las observaciones de las variables restando su media a cada elemento de cada columna. Matricialmente esto se expresa de la siguiente manera:
Aquí el término es el producto de una matriz cuyo valor de todos sus 20 elementos es el número 1. Esta matriz de unos multiplica por la izquierda al vector de medias traspuesto. Recuerda que en álgebra matricial el orden de los factores sí importa. Esto hace que a cada elemento de la matriz se le reste su media correspondiente. La matriz resultante es la matriz de observaciones centradas . Si no conocemos la podemos estimar. En este caso la estimación del vector de medias de la Tabla 1 hubiera sido
.
Usando la media conocida, en la Figura 4 observamos el resultado de centrar nuestras observaciones. Parece que los datos no han cambiado, pero observa el valor de los ejes.
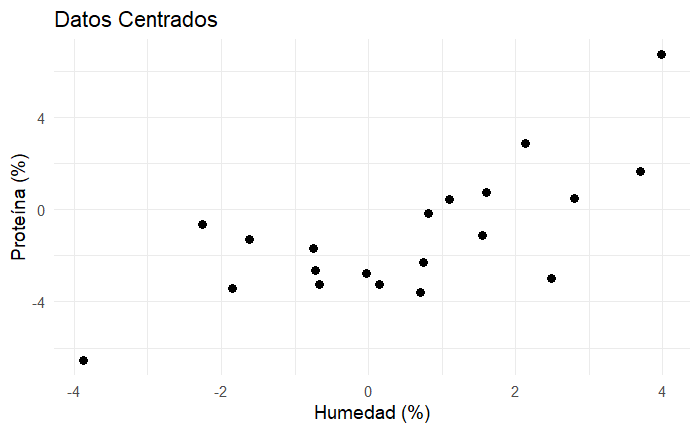
El trabajo que hacemos con el análisis de componentes principales siempre es con las variables centradas, pues lo que nos interesa estudiar es la variabilidad alrededor del centro de masa de nuestro conjunto de observaciones.
Paso 2: Calcular la matriz de varianza-covarianza
Si no conocemos la matriz varianza-covarianza, esta la podemos estimar de los datos utilizando la siguiente ecuación matricial
Esto es simplemente el producto de la matriz de datos centrados transpuesta por la misma matriz de datos centrados sin transponer. Esto genera una matriz donde cada elemento se divide entre los grados de libertad .
La matriz de varianza-covarianza histórica conocida de nuestro ejemplo es
.
En caso de no conocerla, pudiéramos usar los valores estimados de la Tabla 1
.
Evidentemente existe un error al utilizar estimaciones en lugar de los parámetros reales. Sin embargo, a medida que nuestra muestra crece, este error disminuye, pudiendo llegar a no distinguirse el valor estimado del verdadero parámetro. Esta propiedad de los datos es la famosa ley de los grandes números.
Paso 3: Obtener los componentes principales
Los componentes principales, o vectores de variación principales de nuestras observaciones los podemos obtener a partir de los vectores propios, o eigenvectores de la matriz .
Cuando multiplicamos una matriz por un vector, digamos , lo que resulta es un nuevo vector . Así, si un vector lo definimos como una dirección desde el origen hacia las coordenadas que el vector representa, entonces la multiplicación representa un cambio de dirección de a , y es la transformación que genera ese cambio.
Hay vectores que no cambian de dirección, o mejor dicho orientación, cuando son transformados por una matriz. Si acaso, cambian de sentido (lugar hacia donde apuntan), o de escala (que tan largos son), pero su inclinación (dirección u orientación), se mantiene. A estos vectores los llamamos vectores propios, y se definen como
.
Esto es, un eigenvector es un vector asociado a una matriz con una propiedad particular, se trata de un vector especial que no cambia de orientación, aunque sí puede cambiar de magnitud y sentido. Este cambio de magnitud y sentido están definidos por el valor de y el signo de . El valor es conocido como eigenvalor, o valor propio, y su valor está asociado al vector .
Los eigenvectores de una matriz representan direcciones invariantes de la transformación lineal asociada, en las cuales la acción de la matriz se reduce a un escalamiento. Los eigenvalores indican el factor de escala en cada una de estas direcciones.
El cálculo práctico de los vectores y valores propios en dimensiones moderadas o grandes se realiza mediante algoritmos numéricos implementados en software especializado, como R, Python o Minitab.
En la práctica, puedes calcularlos a mano en casos de matrices , y a veces , pero para dimensiones mayores no es viable hacerlo manualmente.
Algunas opciones prácticas para calcularlos son:
- Usando la función de R
eigen()o directamente en PCA de R con prcomp(). - Usando Python import numpy as np y np.linalg.eig().
- Excel es muy limitado, pero se pueden usar complementos o el Solver. No apto para PCA serio.
- Calculadoras simbólicas como Wolfram Alpha también te ayudan a calcular los vectores y valores propios.
Utilizando R eigen() en R con la matriz de varianza-covarianza histórica obtenemos una matriz con vectores propios
,
y varios valores propios
.
El primer vector propio es
,
y su valor propio asociado es 10.405.
El segundo vector propio es
,
y su valor propio asociado es 2.595.
Si observas el primer valor propio notarás que . Así mismo . Esta operación, expresada matricialmente como , se le conoce como la norma de un vector, y no es otra cosa que la distancia euclidiana que forma un vector respecto al origen. Que estas normas, o distancias, sean igual a 1 en el caso de los vectores propios no es coincidencia, así se obtienen, para que expresen un crecimiento unitario y así la escala del vector se deja en el valor de .
Observarás también que en este caso hay dos vectores propios. Existe un vector propio por cada dimensión o tamaño de la matriz , y por cada vector propio hay un valor propio asociado. Cuando estos se obtienen, se guardan siguiendo el mismo patrón, el primer vector propio, , es la primera columna de , y tiene asociado el valor propio más grande, definido como . La segunda columna de es , y tiene asociado el segundo valor propio más grande, definido como . En caso de que tenga más columnas, tendremos más vectores propios cuya magnitud asociada se irá mostrando en forma decreciente.
Al primer vector propio de , el que tiene el valor propio más grande, lo llamamos el primer componente principal o simplemente PC1. Al segundo vector propio de lo llamamos segundo componente principal o PC2.
Gráficamente, si ubicamos estos vectores en el punto central de nuestros datos y trazamos líneas a lo largo de estos vectores obtenemos la Figura 5.
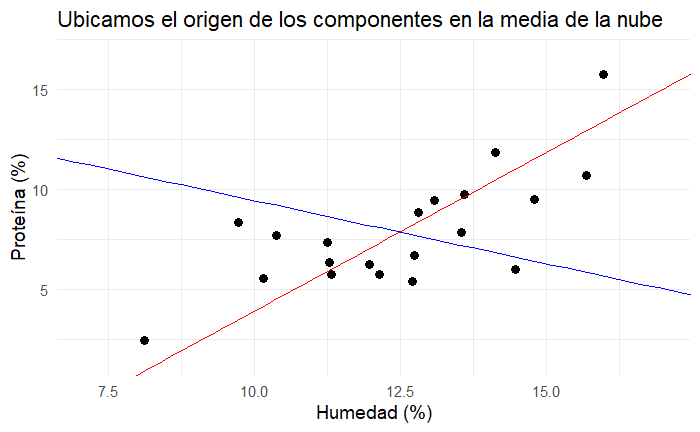
Debido a que los ejes de la Figura 5 tienen escalas diferentes, es difícil apreciar la perpendicularidad de los vectores que hemos encontrado. Pero créeme, como veremos más adelante, son perpendiculares entre sí, que la escala de los ejes no te engañe.
Nota Técnica: Descomposición Espectral
Al proceso de obtener los vectores y valores propios de una matriz también se le puede encontrar con el nombre de una técnica matricial que hace uso de ellos llamada descomposición espectral o diagonalización matricial.
Es un concepto muy útil para entender porqué los valores y vectores propios aparecen con tanta frecuencia cuando se trabaja con matrices. En palabras simples: muchas matrices, como la matriz de varianza-covarianza, se pueden re-expresar en términos de operaciones con vectores y valores propios.
Los conceptos de descomposición espectral y diagonalización matricial se refieren a lo mismo: descomponer una matriz en un producto de matrices creadas a partir de vectores y valores propios. Este proceso va así:
Sea una matriz simétrica.
La descomposición espectral establece que puede re-escribirse como:
donde:
- es una matriz ortogonal cuyas columnas son los eigenvectores de . Por matriz ortogonal definimos que los vectores son perpendiculares entre sí y su norma es unitaria. Así, para un vector tenemos que .
- es una matriz diagonal cuyos elementos de la diagonal son los eigenvalores de . El resto de los elementos de esta matriz son 0’s.
- El orden de los vectores sigue el orden de las magnitudes de los valores propios: es el vector propio con el valor propio más grande , seguido por con el segundo valor propio más grande , y así se sigue en orden descendente.
Paso 4. Proyectar
Podemos proyectar, observa la Figura 6, nuestras observaciones en nuestros componentes principales, como si fueran nuevos ejes de coordenadas.
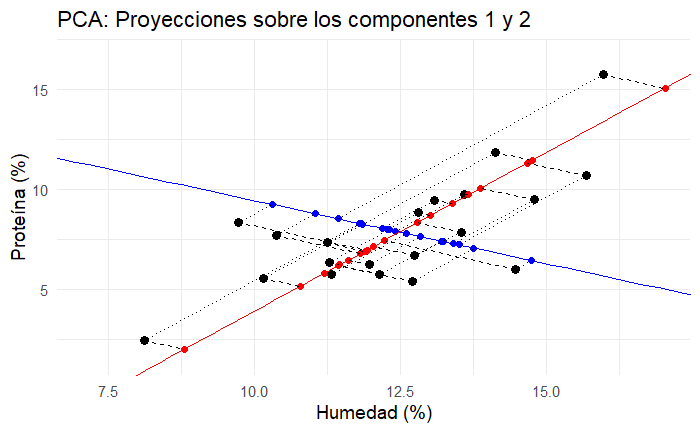
Las coordenadas de nuestras observaciones en los nuevos ejes definidos por los componentes principales las encontramos multiplicando nuestra matriz de observaciones centradas por la matriz formada por los vectores propios
En nuestro ejemplo, recordemos que los vectores propios son
.
por lo tanto, las columnas de están dadas por
,
,
donde es la primera columna de y la segunda columna. A estos valores, y se les conoce como puntajes o por su término en inglés scores. Observa el primer score está construido por la suma del producto de cada elemento del vector propio 1 por cada una de las variables siguiendo el orden en que están definidas. Así mismo se obtiene el segundo score del segundo vector propio.
Para observar mejor la perpendicularidad de los componentes y las proyecciones de las observaciones podemos ajustar los ejes para que estén en la misma escala, como se ve en la Figura 7.
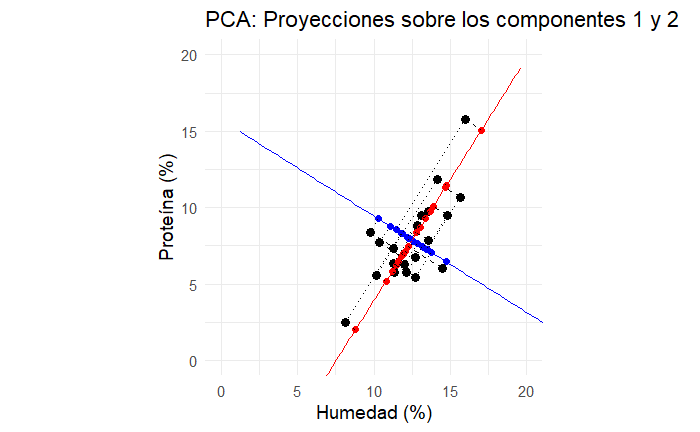
Si graficamos las coordenadas que nos dan estas proyecciones observamos que nuestros datos siguen intactos, pero ahora están rotados. Observa en la Figura 8 esta rotación que coloca la mayor variación en el eje de la abscisa, el eje X con el componente principal 1 (PC1), y la ordenada con el segundo componente (PC2).
Observa que no hay correlación lineal entre los componentes. La correlación lineal entre componentes es exactamente 0 por diseño, siempre. En la Figura 9 se muestra una comparación de la rotación creada gracias a los scores con las observaciones en sus dimensiones originales.
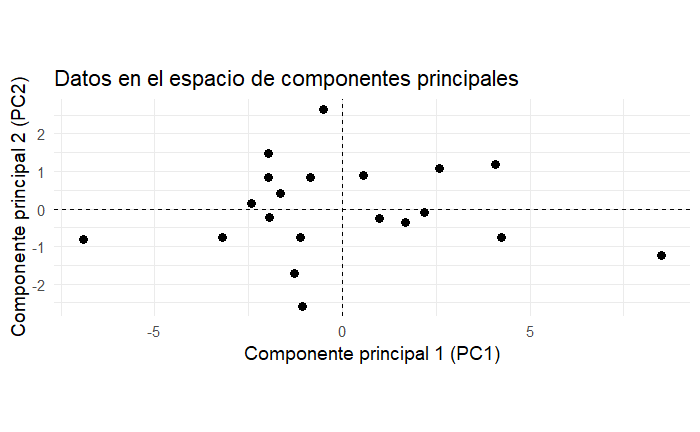
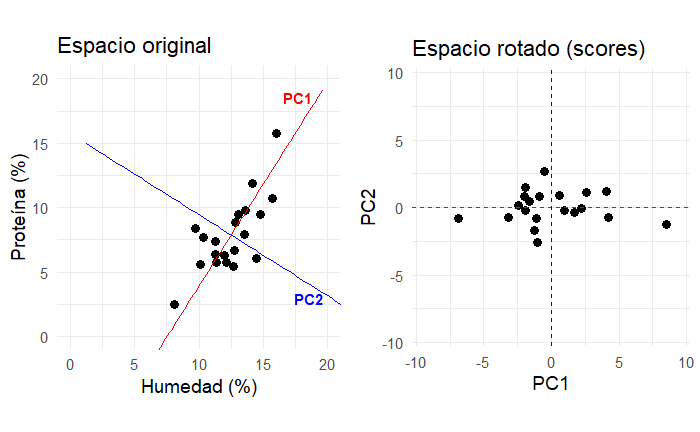
Varias veces habíamos mencionado que los valores propios, las , representan la escala de los vectores propios. En el caso de los componentes principales, esta escala es la varianza. Así, la varianza de los datos en el primer componente, , está dada por . La varianza de los datos en el segundo componente está dada por .
Paso 5. Usar los componentes para algo práctico
El ACP tiene múltiples usos en el mundo del análisis multivariado. Muchos de estos usos están listados al inicio del documento donde el ACP es la llave para acceder a ellos. Aquí es donde se vuelve útil el ACP. Sin embargo, es un paso en el que no ahondaremos para evitar sobrecargar la lectura.
Para no reducir la importancia de estas aplicaciones, dejaré su discusión para mis próximos artículos.
Hasta el momento hemos recorrido los pasos que nos llevan a entender la variabilidad de nuestras observaciones. Hemos identificado las direcciones en que principalmente varían nuestros datos, y hemos obtenido ecuaciones que caracterizan esas direcciones de variación principales. Por sí mismo, este análisis nos genera entendimiento de nuestros datos. Un entendimiento que, bien direccionado, nos deberá llevar a una toma de decisiones más informada.
Resumen de Ecuaciones
Podemos resumir el análisis de componentes principales de la siguiente manera
Sea la matriz de datos.
Paso 1. Centramos
Paso 2. Calculamos la matriz de varianza-covarianza
Paso 3. Obtenemos los componentes principales a partir de los vectores propios.
Paso 4. Proyectamos nuestros datos en el sistema de coordenadas definido por los componentes principales.
Paso 5. Usamos los componentes para algo práctico como: reducir dimensiones, calcular distancias estandarizadas, identificar conglomerados, regresión de componentes principales, clasificación por componentes principales, y, por supuesto, control multivariado de procesos.
Conclusión
Ya dimos el primer paso, generar entendimiento. El ACP es el primer paso, teórico si quieres, al mundo aplicado del análisis multivariado. Son la base para entender la variación de nuestras observaciones en sus términos lineales más elementales.
El entendimiento y la obtención de los componentes de variación son análogos a saber calcular la varianza de tus datos univariados. Son el fundamento para lograr la inferencia, modelación, predicción y control de nuestras variables dentro de su complejidad multifactorial.
Ahora sólo nos queda dar uso a lo que hemos aprendido continuando nuestro viaje a través de los métodos de análisis multivariados. ¡Qué lo disfrutes!
Apéndice: Derivación de los Componentes Principales
Los siguientes resultados de álgebra matricial y estadística multivariada son adaptaciones de libro de texto. Los adapté y te los comparto para colocar un poco de rigor y soporte a tantos argumentos que he mencionado en este artículo.
Un problema de optimización
Sea
Definimos una combinación lineal de las variables centradas:
donde es un vector de coeficientes.
El objetivo del primer componente principal es encontrar la dirección que maximiza la varianza de , sujeta a que tenga norma unitaria:
Como
el problema se re-escribe como
¿Cómo se resuelve esta optimización?
Para resolverlo, se construye el lagrangiano. Esta es una técnica de optimización por restricciones, donde se colocan las restricciones dentro de la función objetivo como términos multiplicados por un factor , también llamado factor o multiplicador de Lagrange:
Y para resolver la optimización, siguiendo la técnica del lagrangiano, sólo tenemos que derivar respecto a e igualar a cero:
Por lo tanto,
Esta es precisamente la ecuación de eigenvalores y eigenvectores de la matriz de covarianza .
Pero todavía hay un problema, la ecuación de eigenvalores y eigenvectores tiene muchas soluciones. ¿Con cuál nos quedamos?
¿Con cuál solución nos quedamos?
Como se vio en la sección anterior, las direcciones posibles para dar valor a , y definir como un componente principal son los eigenvectores de .
Sin embargo, hay tantas soluciones a esta optimización como vectores y valores propios hay. De todas estas posibles soluciones, hay sólo un vector propio con el valor propio asociado más grande, el que por definición tiene la mayor escala, resolviendo así el problema de maximización global.
Así, para el primer componente principal se elige el eigenvector asociado al mayor eigenvalor:
De forma análoga, el segundo componente principal se obtiene maximizando
sujeto a
lo que conduce al eigenvector asociado al segundo mayor eigenvalor. Y el proceso se repite para cada componente.
Si ignoramos la restricción de ortogonalidad con el primer componente principal , la solución a la optimización ya la sabemos: son los vectores propios.
Entre las propiedades conocidas de los vectores propios está que son ortogonales entre sí. Así que la solución es sólo elegir entre los vectores propios restantes. ¿Cuál elegimos? Pues el que tenga el siguiente valor propio más grande, porque como ya se demostró este sería el que contiene la mayor variabilidad, resolviendo así el problema de optimización global.
Repetimos este proceso restringiendo que las nuevas soluciones sean ortogonales con las que vamos obteniendo hasta obtener que los componentes principales son en realidad todos los vectores propios.
¿Cómo sabemos que la varianza de los componentes son los valores propios?
Una propiedad de los vectores propios es que , por lo que se tiene
Esto es válido asumiendo que la norma del vector .
Esto se repite para cada componente. De esta manera se demuestra que la varianza del componente principal es el eigenvalor asociado.
Nota de lenguaje
Existe una ambigüedad real en la literatura de ACP, incluyendo este mismo artículo, con el término «componente principal», que puede usarse con frecuencia para dos cosas distintas, aunque relacionadas. En la práctica componente principal suele referirse a:
- Vectores propios: direcciones principales.
- Scores: componentes proyectados.
El contexto te ayudará a definir si se habla de uno u otro concepto.
Además, algunos autores, para hacer énfasis en la carga o contribución que genera una variable en la ecuación que define un componente proyectado, añaden el concepto de loadings para referirse a los elementos individuales de los vectores propios.
Ten en cuenta que estas definiciones pueden tener ligeras variaciones y es importante identificar el contexto con que cada autor trabaja. Pero no te preocupes, los buenos autores definen estos conceptos a medida que los presentan en sus trabajos.